Synthetische Daten: Dies sind von künstlicher Intelligenz generierte Forschungsdaten, für die kein einziger Mensch aktiv befragt wurde. Was auf den ersten Blick noch spielerisch oder experimentell wirkt, hat derzeit enorme Sprengkraft: Denn immer häufiger werden synthetische Daten in der aktuellen Diskussion als Ersatz für klassische Marktforschung gehandelt. Warum sollte man noch in aufwändige Befragungen investieren, wenn es auch auf Knopfdruck geht?
Aber sind synthetische Daten wirklich dieser Gamechanger für die Marktforschung – ähnlich disruptiv wie vor einigen Jahrzehnten der Schwenk auf digitale Befragungskanäle? Oder eher ein überzogenes Versprechen bzw. lediglich ein weiterer Evolutionsschritt in der Branche? Sicher ist: Wenn es zum Thema „Synthetische Daten“ kommt, schlagen die Wogen in der Diskussion derzeit hoch.
Einige Verfechter der neuen Technologie, mehrheitlich auch in den USA, sehen in synthetischen Daten bereits das Ende klassischer Marktforschung. Andere Forscher und Experten, nicht nur aus der Marktforschung selbst, gehen an dieses Thema mit größerer Skepsis heran und warnen vor vorschnellen Schlüssen.
Lassen Sie uns also etwas Licht ins Dunkel bringen – und zunächst klären, was synthetische Daten überhaupt sind. Und, das werden Sie sehen: Es gibt verschiedene Formen von synthetischen Daten, und diese Unterscheidung wird sehr wichtig sein.
Dann schauen wir auf mögliche Anwendungsfälle in der Marktforschung und auf vielversprechende Ansätze, synthetische und echte Daten miteinander zu verbinden. Wir von Cogitaris sehen dort eine besondere Verantwortung, denn seit unserer Gründung beschäftigen wir uns mit dem wirklich fundierten Einsatz von KI und Data Science in der Marktforschung. Nicht, weil es diese Technologien gibt – sondern gezielt in den Feldern, in denen sie uns für datengetriebene Entscheidungen tatsächlich weiterhelfen.
Was sind synthetische Daten? Definition und Funktionsweise
Beginnen wir gleich mal mit der Definition. Wenn wir von synthetischen Daten sprechen, meinen wir künstlich erzeugte Informationen, die durch algorithmische Verfahren und KI-Modelle generiert werden, um echte Daten zu imitieren. Diese Definition ist bewusst breiter gefasst als nur „KI befragt KI“, denn synthetische Daten umfassen ein ganzes Spektrum verschiedener Ansätze und Technologien.
Die Bandbreite synthetischer Daten
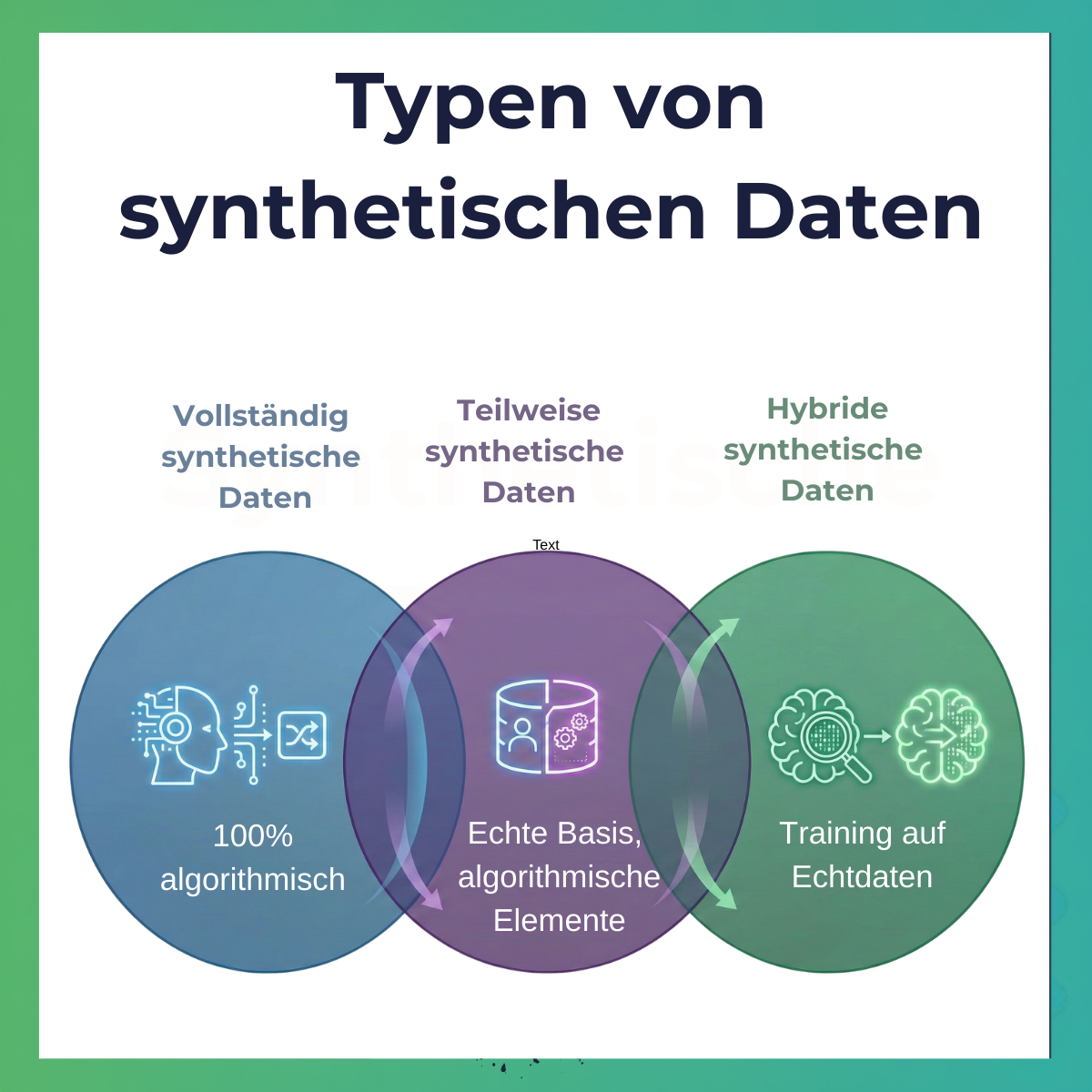
Synthetische Daten sind keineswegs eine einheitliche Kategorie. Tatsächlich existieren verschiedene Typen, die sich fundamental in ihrer Herangehensweise unterscheiden:
- Vollständig synthetische Daten werden komplett algorithmisch erzeugt, ohne dass echte Datenpunkte direkt verwendet werden. Stellen Sie sich vor, Sie möchten Kundendaten für Testzwecke generieren: Ein Algorithmus würde komplett neue Namen, Adressen, Kaufhistorien und Präferenzen erfinden, die statistisch plausibel sind, aber keiner realen Person entsprechen. In der Marktforschung würde das bedeuten: Das KI-Modell generiert Befragtenantworten ausschließlich basierend auf seinen Trainingsdaten, ohne jemals einen einzigen echten Vertreter der Zielgruppe gesehen zu haben.
- Teilweise synthetische Daten kombinieren echte Datenpunkte mit algorithmisch generierten Elementen. Hier werden sensible oder fehlende Informationen durch synthetische Werte ersetzt, während andere Teile der Daten echt bleiben. In der Marktforschung könnte das bedeuten, dass demografische Daten von echten Befragten stammen, während deren Antworten auf hypothetische neue Produktkonzepte synthetisch ergänzt werden.
- Hybride synthetische Daten – und hier wird es für unseren Kontext besonders relevant – nutzen echte Daten als Trainingsgrundlage, um dann neue, synthetische Datenpunkte zu generieren, die die statistischen Eigenschaften und Muster der Originaldaten bewahren. Das ist konzeptionell das, was Ansätze wie MyPersona IQ tun: Sie starten mit echten Interviews und nutzen diese als Basis, um darauf aufbauend KI-gestützte, interaktive Modelle zu entwickeln.
Eine sehr gute Einführung in das Thema bietet auch IBM mit dem Artikel: Was sind synthetische Daten?
Generierungsmethoden: Mehr als nur Sprachmodelle
Die Erzeugung synthetischer Daten beschränkt sich nicht auf das bloße Befragen von Large Language Models wie ChatGPT oder Claude. Tatsächlich kommen verschiedene technische Ansätze zum Einsatz:
- Generative Adversarial Networks (GANs) sind ein häufig eingesetztes Verfahren, bei dem zwei neuronale Netze gegeneinander arbeiten: Ein Generator erstellt synthetische Daten, während ein Diskriminator versucht zu erkennen, ob die Daten echt oder synthetisch sind. Durch diesen Wettbewerb werden die synthetischen Daten immer realistischer. GANs werden beispielsweise eingesetzt, um realistische Bilder, Videos oder auch strukturierte Datensätze zu erzeugen.
- Variational Autoencoders (VAEs) lernen die zugrundeliegende Wahrscheinlichkeitsverteilung echter Daten und können dann neue Datenpunkte aus dieser gelernten Verteilung generieren. Sie komprimieren zunächst die Eingangsdaten in eine latente Repräsentation und rekonstruieren dann daraus neue, synthetische Datenpunkte.
- Large Language Models (LLMs) wie GPT-4, Claude oder Gemini sind die Technologie, die im Kontext der Marktforschung am häufigsten zum Einsatz kommt. Diese Modelle haben während ihres Trainings riesige Mengen an Texten aus dem Internet verarbeitet und dabei statistische Muster darüber gelernt, wie Menschen denken, argumentieren und auf Fragen reagieren. Sie können nicht nur Text generieren, sondern auch in Rollen schlüpfen und Perspektiven simulieren.
- Regel-basierte Systeme nutzen definierte Regeln und Algorithmen, um synthetische Daten zu erzeugen. Während diese Methode weniger flexibel ist, hat sie den Vorteil höherer Nachvollziehbarkeit und Kontrolle.
- Diffusionsmodelle sind eine neuere Klasse von Generierungsverfahren, die schrittweise Rauschen zu Daten hinzufügen und dann lernen, diesen Prozess umzukehren, um neue Samples zu erzeugen.
Der typische Ablauf in der Marktforschung für den Einsatz von synthetischen Daten
Fokussieren wir uns nun auf den spezifischen Einsatz in der Marktforschung, wo bislang häufig primär LLM-basierte Ansätze zum Einsatz kommen. Der typische Ablauf sieht etwa so aus:
- Zunächst definieren Sie als Forscher sehr präzise, wen Sie befragen möchten. Sie erstellen ein detailliertes Profil Ihrer Wunschperson, beispielsweise: „Geschäftsführerin eines mittelständischen Maschinenbauunternehmens, zwischen 45 und 60 Jahre alt, technikaffin, mit internationaler Geschäftserfahrung, fokussiert auf Digitalisierung, unter Margendruck.“ Je spezifischer diese Definition, desto besser kann das Modell die Rolle ausfüllen.
- Dann beauftragen Sie das KI-Modell – technisch gesprochen: Sie formulieren einen Prompt – sich in diese Person hineinzuversetzen und aus deren Perspektive auf Ihre Fragen zu antworten. Dieser Prompt ist entscheidend: Er definiert nicht nur die demografischen Merkmale, sondern idealerweise auch Denkweisen, typische Sorgen, Prioritäten und Entscheidungskriterien der simulierten Person.
- Das Sprachmodell erstellt daraufhin einen „digitalen Zwilling“ – einen künstlichen Gesprächspartner mit spezifischen Hintergründen, Präferenzen und Denkmustern. Dieser digitale Zwilling wird dann zu Ihrem Thema „befragt“. Er liefert Antworten, die darauf basieren, was das Modell aus seinen Trainingsdaten über Personen mit ähnlichen Profilen „gelernt“ hat.
Wichtig zu verstehen: Das Modell greift dabei nicht auf eine Datenbank mit echten Antworten echter Geschäftsführerinnen zurück. Stattdessen generiert es Antworten basierend auf statistischen Mustern aus seinen Trainingsdaten. Es hat Millionen von Texten gesehen – von LinkedIn-Posts über Fachartikel bis hin zu Forenbeiträgen – und „weiß“ dadurch, wie sich jemand mit diesem Profil wahrscheinlich ausdrücken würde. Aber es hat keine direkte Verbindung zu echten Erfahrungen, Emotionen oder Kontexten.
Am Ende aggregieren Sie die Antworten vieler solcher digitaler Zwillinge und werten sie aus, so als hätten Sie eine klassische Befragung durchgeführt. Sie erstellen Häufigkeitsverteilungen, berechnen Durchschnittswerte, identifizieren Cluster – genau wie bei echten Daten.

Echte versus synthetische Daten: Die entscheidenden Unterschiede
Um die Natur synthetischer Daten wirklich zu verstehen, müssen wir die fundamentalen Unterschiede zu echten Daten herausarbeiten:
- Echte Daten stammen von realen Ereignissen, Menschen oder Prozessen. Jeder Datenpunkt hat eine konkrete Quelle in der Realität. Wenn ein Geschäftsführer in einer Befragung angibt, dass ihm Lieferzuverlässigkeit wichtiger ist als Preis, dann basiert diese Aussage auf seinen tatsächlichen Erfahrungen – vielleicht hat sein Unternehmen vor zwei Jahren einen wichtigen Auftrag verloren, weil ein Lieferant nicht rechtzeitig lieferte. Diese Geschichte, diese emotionale Prägung steckt in der Antwort, auch wenn sie nicht explizit erzählt wird.
- Synthetische Daten sind künstlich generiert und haben keine direkte Entsprechung in der Realität. Sie imitieren statistische Eigenschaften echter Daten, aber jeder einzelne Datenpunkt ist eine Kreation des Algorithmus. Der synthetische Geschäftsführer, der sagt, Lieferzuverlässigkeit sei wichtiger als Preis, basiert diese Aussage nicht auf einer echten Erfahrung, sondern darauf, dass das Modell gelernt hat, dass Geschäftsführer im Maschinenbau statistisch häufig diese Priorität äußern.
Diese Unterscheidung mag akademisch erscheinen, ist aber praktisch hochrelevant. Echte Daten enthalten Rauschen, Widersprüche, Ausreißer – all das, was die Komplexität echter menschlicher Entscheidungen widerspiegelt. Synthetische Daten sind oft zu glatt, zu konsistent, zu „vernünftig“. Sie erfassen den statistischen Durchschnitt, aber nicht die individuellen Geschichten und Kontexte, die oft entscheidend sind.
Anwendungsfelder für synthetische Daten jenseits der Marktforschung
Um die Bandbreite synthetischer Daten zu verstehen, lohnt ein Blick auf Anwendungen außerhalb der Marktforschung:
- In der Softwareentwicklung werden synthetische Testdaten genutzt, um Anwendungen unter verschiedenen Bedingungen zu testen, ohne echte Kundendaten verwenden zu müssen – wichtig für Datenschutz und Sicherheit.
- Im Gesundheitswesen ermöglichen synthetische Patientendaten die Entwicklung und das Training medizinischer KI-Systeme, ohne echte Patientendaten zu gefährden. In der Finanzbranche helfen synthetische Transaktionsdaten beim Training von Betrugserkennung ssystemen.
- In der Bildverarbeitung werden synthetische Bilder genutzt, um Computer-Vision-Algorithmen zu trainieren – deutlich kostengünstiger und schneller, als Millionen echter Fotos zu annotieren.
Diese Anwendungen zeigen: Synthetische Daten haben durchaus ihre Berechtigung und ihren Wert. Die Frage ist immer: Für welchen Zweck werden sie eingesetzt, und wie kritisch ist die Anforderung an Authentizität und Realitätstreue?
Typische Anwendungsfelder in der Marktforschung
In der aktuellen Forschungspraxis werden synthetische Daten vor allem in einigen spezifischen Bereichen eingesetzt. Schauen wir uns diese genauer an, immer mit einem kritischen Blick auf ihre Eignung.
- Silicon Samples – künstliche Stichproben – sind ein wichtiges Einsatzfeld. Forscher können damit schnell erste Hypothesen testen oder einen Fragebogenentwurf auf seine Verständlichkeit prüfen, bevor sie in die teure Feldphase gehen. Stellen Sie sich vor, Sie haben einen Fragebogen mit dreißig Fragen entwickelt. Bevor Sie tausend echte Teilnehmer damit konfrontieren, können Sie ihn mit synthetischen Daten testen: Sind die Fragen verständlich formuliert? Erzeugen sie plausible Antwortmuster? Gibt es offensichtliche Probleme im Ablauf? Für solche Pretests können synthetische Daten durchaus sinnvoll sein.
- Replikationsstudien sind ein zweites Anwendungsfeld. Wenn Forscher überprüfen wollen, ob die Ergebnisse einer bereits publizierten Studie reproduzierbar sind, können sie die Studie mit synthetischen Daten nachstellen – deutlich schneller und kostengünstiger als mit einer erneuten Befragung echter Menschen. Allerdings, und das ist wichtig: Wenn eine synthetische Replikation zu anderen Ergebnissen führt, ist damit noch nicht bewiesen, dass die Originalstudie falsch war. Es könnte genauso gut bedeuten, dass die synthetischen Daten die Realität nicht korrekt abbilden.
- Bei der Entwicklung neuer Messskalen kommt synthetische Datengeneration ebenfalls zum Einsatz. Forscher lassen KI-Modelle Vorschläge für Fragebogenitems generieren und diese anschließend von künstlichen Probanden bewerten, um die besten Items zu identifizieren. Die finale Validierung muss aber immer mit echten Daten erfolgen – synthetische Daten können hier allenfalls die Vorauswahl treffen.
- Szenario-Simulationen sind ein weiteres Feld, bei dem verschiedene Markt- oder Produktszenarien durchgespielt werden. Was würde passieren, wenn wir den Preis um 20% senken? Wie würde die Zielgruppe auf ein komplett neues Feature reagieren? Synthetische Daten können hier erste Orientierung bieten, aber die Unsicherheit ist hoch – oft zu hoch für echte Entscheidungen.
- Bei qualitativen Vorstudien werden synthetische Daten teilweise als Ersatz oder Ergänzung für klassische Fokusgruppen oder Tiefeninterviews diskutiert. Hier ist besondere Vorsicht geboten: Die Tiefe und Authentizität echter qualitativer Forschung lässt sich kaum synthetisch replizieren. Was fehlt, sind die spontanen Reaktionen, die nonverbalen Signale, die Momente des Zögerns oder der Begeisterung, die oft mehr verraten als die Worte selbst.
- Ein relativ neues, aber wachsendes Feld ist das Training und die Kalibrierung von KI-Systemen selbst. Synthetische Daten können helfen, Bias in Algorithmen zu identifizieren und zu reduzieren, indem bewusst diverse und ausgewogene Datensätze generiert werden.
- Schließlich werden synthetische Daten auch für Datenschutz-konforme Analysen eingesetzt. Wenn echte Daten aus Datenschutzgründen nicht geteilt werden können, können synthetische Daten, die die statistischen Eigenschaften der Originaldaten bewahren, eine Alternative bieten – etwa für Forschungskooperationen oder regulatorische Prüfungen.
Was all diese Anwendungen eint: Sie funktionieren am besten, wenn es um statistische Muster, um Durchschnittswerte, um grundlegende Zusammenhänge geht. Sobald es um Tiefe, um individuelle Geschichten, um die Nuancen echter menschlicher Entscheidungen geht, stoßen synthetische Daten schnell an ihre Grenzen.
Versprechen und Realität für den Einsatz von synthetischen Daten
Die Flexibilität synthetischer Daten ist beachtlich. Sie sind rund um die Uhr verfügbar; eine zusätzliche Frage lässt sich jederzeit eingeben und liefert Minuten später Antworten, ohne auf ein Feldteam warten zu müssen. Das Problem der „Survey Fatigue“ entfällt, da digitale Zwillinge beliebig oft befragt werden können, ohne dass die Antwortqualität sinkt. Auch die Anpassung der Stichprobenzusammensetzung ist flexibel: Benötigen Sie mehr Teilnehmer aus einer bestimmten Branche, lassen sich einfach neue digitale Zwillinge mit diesem Profil generieren, was bei klassischen Methoden eine aufwendige neue Rekrutierungswelle bedeuten würde. Theoretisch wird so auch der Zugang zu schwer erreichbaren Zielgruppen simuliert, deren Perspektive sonst nicht erfasst werden könnte.
So beeindruckend die Versprechen synthetischer Daten auch klingen mögen – ihre Eignung als alleinige Grundlage für weitreichende Entscheidungen ist massiv eingeschränkt. Die Probleme sind teilweise fundamentaler Natur.

Das Black-Box-Problem
Sprachmodelle sind Black Boxes. Selbst ihre Entwickler können nicht exakt nachvollziehen, warum das Modell eine spezifische Antwort generiert hat. Die Folgen für seriöse Aussagen mittels synthetischer Daten sind daher gravierend:
- Mangelnde Transparenz: Die wissenschaftliche Forderung nach Nachvollziehbarkeit und Reproduzierbarkeit ist kaum erfüllbar. Es ist unklar, auf welcher Datenbasis das Modell trainiert wurde und welche spezifischen Einflüsse die Antwort bestimmen.
- Fehlende Reproduzierbarkeit: Bei identischer Befragung können je nach Einstellungen und Zufallselementen unterschiedliche Antworten entstehen, was einem Kernprinzip wissenschaftlichen Arbeitens widerspricht.
Fehlende Authentizität
Synthetische Daten basieren auf statistischen Wahrscheinlichkeitsmodellen, nicht auf echten Erfahrungen, Emotionen oder tatsächlichen Denkprozessen realer Menschen.
- Statistische Durchschnitte statt Realität: Das Modell „denkt“ nicht wirklich, sondern berechnet, was eine statistisch wahrscheinliche Antwort wäre. Echte Kaufentscheidungen in der B2B-Welt werden jedoch von komplexen, oft nicht bewussten Einflüssen wie persönlichen Erfahrungen, Bauchgefühl oder Unternehmenskultur geprägt – Ebenen, die synthetische Daten nicht abbilden können.
- Verlust von Nuancen: Kulturelle und kontextspezifische Unterschiede (z.B. mittelständisches Familienunternehmen vs. Tech-Konzern) gehen in den geglätteten Mustern synthetischer Daten verloren.
Mangelnde Reliabilität und Validität
Die Probleme mit Zuverlässigkeit (Reliabilität) und Gültigkeit (Validität) sind gravierend.
- Reliabilitätsprobleme:
- Inkonsistenz: Wiederholte Messungen können bei identischen Eingaben zu unterschiedlichen Ergebnissen führen.
- Halluzinationen: Sprachmodelle erfinden Fakten oder Statistiken, die plausibel klingen, aber falsch sind.
- Modell-Updates: Kontinuierliche Verbesserungen der Modelle verändern die Ergebnisse, was langfristiges Tracking in der Marktforschung unmöglich macht.
- Validitätsprobleme:
- Geringe Construct Validity: Das Modell könnte ein anderes Verständnis von Konzepten wie „Markentreue“ haben als die Zielgruppe.
- Eingeschränkte External Validity: Selbst konsistente synthetische Daten spiegeln nicht zwangsläufig die Realität der echten Zielgruppe wider.
- Fehlende Predictive Validity: Synthetische Daten sagen oft nicht das tatsächliche Verhalten voraus, das eintritt, wenn echtes Geld im Spiel ist.
Der Action Gap: Schöne Grafiken ohne Handlungsrelevanz
Synthetische Daten liefern oft schnell visuell ansprechende Ergebnisse, denen jedoch die Handlungsrelevanz fehlt.
- Lücke zwischen Daten und Aktion: Dieses „Action Gap“ entsteht, weil die Modelle zwar statistisch plausible, aber keine kaufentscheidenden Vorbehalte, Zweifel oder politischen Faktoren der B2B-Welt erfassen.
- Trügerische Sicherheit: Unternehmen riskieren Fehlentscheidungen (z.B. sechsstellige Investitionen in ein neues Produkt), weil die synthetischen Erkenntnisse die Realität der Zielgruppe nicht adäquat abbilden.
Ethische und methodische Bedenken
Zusätzlich existieren ethische und methodische Herausforderungen:
- Datenschutz und Bias: Die Transparenz über die Trainingsdaten ist gering. Zudem neigen Modelle dazu, in den Trainingsdaten enthaltene Vorurteile (Bias) zu reproduzieren und zu verstärken, was zu systematisch verzerrten Forschungsergebnissen führt.
- Wissenschaftliche Skepsis: Renommierte wissenschaftliche Journals fordern zunehmend strenge Auflagen oder lehnen Studien, die ausschließlich auf rein synthetischen Primärdaten basieren, kategorisch ab.
Stand der Forschung: Was zeigen Validierungsstudien?
Nachdem wir die theoretischen Probleme synthetischer Daten ausführlich diskutiert haben, stellt sich natürlich die Frage: Was sagt eigentlich die empirische Forschung? Gibt es bereits systematische Untersuchungen, die zeigen, wie gut oder schlecht synthetische Daten tatsächlich funktionieren? Die Antwort ist: Ja, es gibt erste Studien, und deren Ergebnisse sind gemischt und sollten uns zur Vorsicht mahnen.
Replikationsstudien (AI-REPs)
Ein interessanter Ansatz zur Validierung synthetischer Daten sind sogenannte AI-Replikationen, kurz AI-REPs. Die Grundidee ist einfach: Man nimmt eine bereits publizierte Studie mit echten Teilnehmern, repliziert sie mit synthetischen Daten und vergleicht dann die Ergebnisse. Wenn die synthetischen Daten zu denselben Schlussfolgerungen führen wie die echten Daten, spricht das für ihre Validität.
Zunächst die positiven Befunde aus den ersten Studien: Bei einigen gut etablierten und standardisierten Messskalen zeigten sich tatsächlich ähnliche Faktorstrukturen. Wenn beispielsweise eine Skala zur Markenpersönlichkeit mit echten Daten fünf Dimensionen ergab, fand man mit synthetischen Daten ebenfalls diese fünf Dimensionen. Auch grundlegende Zusammenhänge – etwa dass eine stärkere Brand Heritage zu höherer Kaufabsicht führt – ließen sich teilweise nachbilden.
Doch sobald es komplexer wurde, zeigten sich in den untersuchten Studien erhebliche Probleme. Die Effektgrößen – also die Stärke der gemessenen Zusammenhänge – wichen systematisch ab. Was in den echten Studien einen mittleren Effekt zeigte, ergab in der synthetischen Replikation vielleicht einen starken oder einen schwachen Effekt. Das ist nicht nur ein akademisches Problem: Wenn Sie auf Basis einer Effektgröße berechnen, wie viel Budget Sie in eine Maßnahme investieren sollten, kann so eine Abweichung zu massiven Fehlentscheidungen führen.
Noch problematischer waren Interaktionseffekte. In der Realität ist es oft so, dass der Effekt von Variable A auf Variable B davon abhängt, welchen Wert Variable C hat. Solche komplexen Wechselwirkungen bilden synthetische Daten häufig nicht korrekt ab. Sie reproduzieren vielleicht die Haupteffekte einigermaßen, aber die subtilen Interaktionen, die in der Praxis oft entscheidend sind, gehen verloren oder werden falsch dargestellt.
Besonders auffällig war auch, dass kulturelle Unterschiede in synthetischen Daten nivelliert wurden. Mehrere Untersuchungen, die mit echten Teilnehmern deutliche Unterschiede zwischen deutschen und japanischen Managern gezeigt hatten, ergaben mit synthetischen Daten viel geringere Unterschiede. Das Modell schien kulturelle Eigenheiten zu glätten und einer Art „globaler Durchschnittsperson“ anzunähern.
Vergleichsstudien: Synthetisch vs. Real
Eine andere Herangehensweise sind direkte Vergleichsstudien, bei denen dieselbe Fragestellung parallel mit echten und synthetischen Teilnehmern untersucht wird. Peng und Kollegen haben 2025 eine groß angelegte Studie mit sogenannten „Digital Twins“ durchgeführt – besonders ausgefeilten synthetischen Profilen.
Die Ergebnisse waren ernüchternd differenziert. Zunächst eine wichtige methodische Erkenntnis: Selbst wenn synthetische Daten in Einzelfällen mit realen Daten korrelieren, bedeutet das noch lange nicht, dass sie die zugrundeliegenden psychologischen oder ökonomischen Mechanismen korrekt abbilden. Es könnte auch reiner Zufall sein oder das Modell könnte aus den falschen Gründen zur richtigen Antwort kommen.
Ein zentraler Befund war: Je spezifischer der Kontext, desto schlechter die Übertragbarkeit. Bei sehr allgemeinen Fragen zu weit verbreiteten Konsumgütern funktionierten synthetische Daten teilweise akzeptabel. Aber je spezialisierter die Fragestellung – etwa B2B-Kaufentscheidungen in einer Nischenbranche mit hochkomplexen technischen Produkten – desto deutlicher wurden die Grenzen. Die Modelle hatten einfach nicht genug spezifisches Wissen über diese Nischenkontexte in ihren Trainingsdaten.
Auch der Fragetyp machte einen enormen Unterschied. Faktenfragen – etwa „Welche Marken kennen Sie in dieser Kategorie?“ – wurden von synthetischen Daten deutlich besser beantwortet als komplexe Einstellungsfragen. Fragen, die tiefere emotionale Bewertungen oder Abwägungen zwischen widersprüchlichen Zielen erforderten, waren für synthetische Daten besonders schwierig.
Die Forscher kamen zu dem Schluss, dass synthetische Daten durchaus ein nützliches Werkzeug sein können – aber eben nur ein Werkzeug unter vielen, nicht ein Ersatz für echte Forschung. Ihre Stärken liegen in explorativen Phasen und beim Testen von Hypothesen. Für finale Entscheidungen sind sie nach aktuellem Stand ungeeignet.
Journal-Policies: Die zunehmende Skepsis
Die Zurückhaltung der wissenschaftlichen Community zeigt sich besonders deutlich in den Richtlinien führender Fachzeitschriften. Diese Journals sind gewissermaßen die Qualitätswächter der Forschung, und ihre Haltung zu synthetischen Daten ist ein wichtiger Indikator dafür, wie die Wissenschaft diese Technologie bewertet.
Emerald Publishing hat beispielsweise sehr klare Anforderungen formuliert. Wer synthetische Daten verwenden möchte, muss vollständige Transparenz über alle verwendeten KI-Werkzeuge bieten. Die genauen Prompts – also die Anweisungen an das Sprachmodell – müssen dokumentiert werden. Auch die verwendeten Modelle und deren Versionen müssen angegeben werden, weil sich, wie wir gesehen haben, die Ergebnisse zwischen verschiedenen Modellen und Versionen unterscheiden können.
Darüber hinaus verlangt das Journal eine zusätzliche Validierung durch konventionelle Methoden. Synthetische Daten allein reichen nicht – sie müssen durch echte Daten zumindest stichprobenartig bestätigt werden. Und die Autoren müssen explizit begründen, warum synthetische Daten für ihre Fragestellung notwendig waren. „Wir wollten Zeit und Geld sparen“ gilt nicht als ausreichende Begründung.
Viele andere Top-Journals gehen noch weiter und untersagen derzeit die Verwendung rein synthetischer Primärdaten komplett. Sie akzeptieren synthetische Daten nur für methodische Vorstudien oder als Ergänzung zu echten Daten, nicht als alleinige Grundlage einer Studie.
Diese Skepsis ist nicht willkürlich. Sie reflektiert die berechtigten Zweifel, ob synthetische Daten die Qualitätsstandards erfüllen können, die für wissenschaftliche Publikationen notwendig sind. Und was für wissenschaftliche Publikationen gilt, sollte erst recht für praktische Managemententscheidungen gelten, die möglicherweise Millionen Euro auf dem Spiel haben.
Der hybride Ansatz: Reale Substanz mit KI-Power
Nach dieser ausführlichen Kritik an rein synthetischen Daten könnte der Eindruck entstehen, dass KI in der Marktforschung keinen Platz hat. Das wäre aber der falsche Schluss. Die Technologie ist da, sie ist mächtig, und sie wird nicht wieder verschwinden. Die Frage ist also nicht, ob wir KI nutzen, sondern wie wir sie klug und verantwortungsvoll einsetzen können.
Die Antwort liegt in hybriden Ansätzen, die das Beste aus beiden Welten kombinieren: die Authentizität, Tiefe und Kontextspezifität echter Menschen mit der Skalierbarkeit, Geschwindigkeit und Analysekraft künstlicher Intelligenz. Statt KI als Ersatz für echte Forschung zu sehen, nutzen hybride Ansätze KI als Verstärker und Werkzeug, das auf einem soliden Fundament echter Daten aufsetzt.
Wir als Marktforschungsinstitut setzen seit unserer Gründung 2007 auf den verantwortungsvollen Einsatz von KI – mit Erfolg! Und so können wir auch aus unserer Arbeit erfolgreiche hybride Ansätze in der Marktforschung zeigen.
Das Prinzip: Authentic Foundation, AI Augmentation
Das Grundprinzip hybrider Ansätze lässt sich in drei Schritten beschreiben, die alle gleichermaßen wichtig sind.
- Der erste Schritt ist absolut fundamental: Start with Reality. Sie beginnen nicht mit einem Algorithmus oder einem abstrakten Modell, sondern mit echten Menschen. Sie führen qualitativ hochwertige Tiefeninterviews mit sorgfältig ausgewählten Vertretern Ihrer Zielgruppe durch. Nicht irgendwelche Menschen, sondern genau die Personen, deren Perspektive Sie verstehen müssen. Wenn Sie Maschinenbauunternehmen als Zielgruppe haben, dann sprechen Sie mit Geschäftsführern und Einkaufsleitern von Maschinenbauunternehmen, nicht mit generischen „B2B-Entscheidern“.
- Der zweite Schritt: Capture Authenticity. Diese Interviews sind nicht oberflächliche Abfragen, sondern tiefgehende Gespräche. Sie erfassen nicht nur Fakten und Meinungen, sondern auch die Art, wie Menschen denken und argumentieren. Die emotionalen Untertöne. Die spezifische Sprache und Terminologie der Branche. Die Alltagslogik, nach der Entscheidungen wirklich getroffen werden, nicht wie sie theoretisch getroffen werden sollten. Den kulturellen und organisatorischen Kontext, in dem sich die Befragten bewegen.
- Erst im dritten Schritt kommt die KI ins Spiel: Augment with AI. Die reale Substanz aus den Interviews wird nun mit KI-Technologie kombiniert. Das Ziel ist nicht, die echten Daten zu ersetzen, sondern sie zu skalieren und interaktiv nutzbar zu machen. Die KI dient als Werkzeug, um die in den Interviews erfassten Muster, Denkweisen und Argumentationslinien auf neue Fragestellungen anzuwenden.
Der entscheidende Unterschied zu rein synthetischen Daten liegt also darin, dass die KI hier nicht auf generischen Trainingsdaten operiert, sondern auf echten, spezifischen, kontextreichen Daten Ihrer tatsächlichen Zielgruppe. Die KI lernt nicht, wie ein statistischer Durchschnitts-Manager denkt, sondern wie Ihre konkreten Zielkunden denken.
Praxisbeispiel: MyPersona IQ von Cogitaris
Um dieses abstrakte Prinzip greifbar zu machen, schauen wir uns einen konkreten hybriden Ansatz an: MyPersona IQ von Cogitaris. MyPersona IQ von Cogitaris. MyPersona IQ ist eine Lösung von Cogitaris, die es ermöglicht, virtuelle Gespräche mit B2B-Personas zu führen, welche auf echten Marktforschungsdaten basieren. Dieser Ansatz zeigt exemplarisch, wie die Kombination von echter Forschung und KI-Technologie funktionieren kann.
- Der Prozess beginnt mit einer klassischen, aber sehr sorgfältig durchgeführten qualitativen Forschungsphase. Cogitaris führt dreißig oder mehr Tiefeninterviews durch – nicht einfach dreißig beliebige Gespräche, sondern methodisch fundierte Interviews mit nach wissenschaftlichen Kriterien rekrutierten Personen. Die Rekrutierung folgt denselben Standards, die auch in der akademischen Forschung gelten würden. Sie stellen sicher, dass die Gesprächspartner tatsächlich repräsentativ für die Zielgruppe sind, sowohl in demografischer als auch in psychografischer Hinsicht.
- Die Gesprächsführung selbst ist offen und authentisch. Es geht nicht um das starre Abarbeiten eines standardisierten Fragebogens, sondern um echte Gespräche, die in die Tiefe gehen. Die Interviewer sind geschult, nicht nur nach den offensichtlichen Antworten zu fragen, sondern auch die Beweggründe dahinter zu erkunden. Warum hat jemand diese Meinung? Welche Erfahrungen haben dazu geführt? Welche Sorgen oder Hoffnungen stehen dahinter? Solche Gespräche können durchaus eine Stunde oder länger dauern und liefern ein reichhaltiges Material.
- Das Ergebnis sind keine knappen Antworten auf vordefinierte Fragen, sondern ethnografische Einblicke. Sie verstehen nicht nur, was die Zielgruppe denkt, sondern auch wie sie denkt. Sie erfassen die spezifische Sprache, die diese Menschen verwenden. Die emotionalen Reaktionen auf bestimmte Themen. Die Argumentationsmuster, die typisch für diese Gruppe sind. Den Kontext ihres Arbeitsalltags, der ihre Entscheidungen prägt.
Erst nach dieser aufwändigen qualitativen Phase kommt die KI ins Spiel. In einem mehrstufigen Analyse- und Modellierungsprozess werden die Interviews ausgewertet. Zunächst durch klassische qualitative Inhaltsanalyse: Welche Themen tauchen wiederholt auf? Welche Muster zeigen sich? Wie lassen sich die Befragten in verschiedene Typen oder Segmente einteilen?
Diese qualitativen Erkenntnisse werden dann mit Strukturdaten der Zielgruppe kombiniert. Wenn beispielsweise bestimmte Einstellungen häufiger bei Unternehmen einer bestimmten Größe oder Region auftreten, wird dieser Zusammenhang erfasst und modelliert.
Nun erfolgt das eigentliche KI-Training, aber eben nicht mit generischen Daten. Die Sprachmodelle werden mit den ausgewählten Interviewtexten trainiert, mit den identifizierten Typologien und mit den typischen Argumentationsmustern dieser spezifischen Zielgruppe. Das Ergebnis ist eine LLM-basierte Generierung von Personas, die spezifisches Hintergrundwissen über diese Zielgruppe haben – nicht generisches Wissen über „B2B-Entscheider“ im Allgemeinen.
Das Endprodukt ist ein interaktives Zielgruppenmodell. Sie können jederzeit mit diesen Personas in Dialog treten, neue Fragen stellen, Produktideen vorlegen, Claims testen. Die Personas antworten basierend auf dem realen Fundament der Interviews, erweitert und skaliert durch KI. Dabei können Sie zwischen verschiedenen Personas wählen – etwa dem Hauptnutzer, dem Gelegenheitsnutzer oder dem Kunden, der aktuell beim Wettbewerb kauft.
Der große Vorteil: Diese Personas sind 24/7 verfügbar. Wenn Ihrem Kreativteam auch nach Feierabend eine Idee kommt, können sie diese sofort testen. Wenn im Meeting eine Frage auftaucht, kann diese unmittelbar beantwortet werden. Die zeitliche Flexibilität synthetischer Daten wird erreicht, aber eben auf Basis echter, validierter Zielgruppenerkenntnisse.
Der entscheidende Unterschied zu rein synthetischen Daten
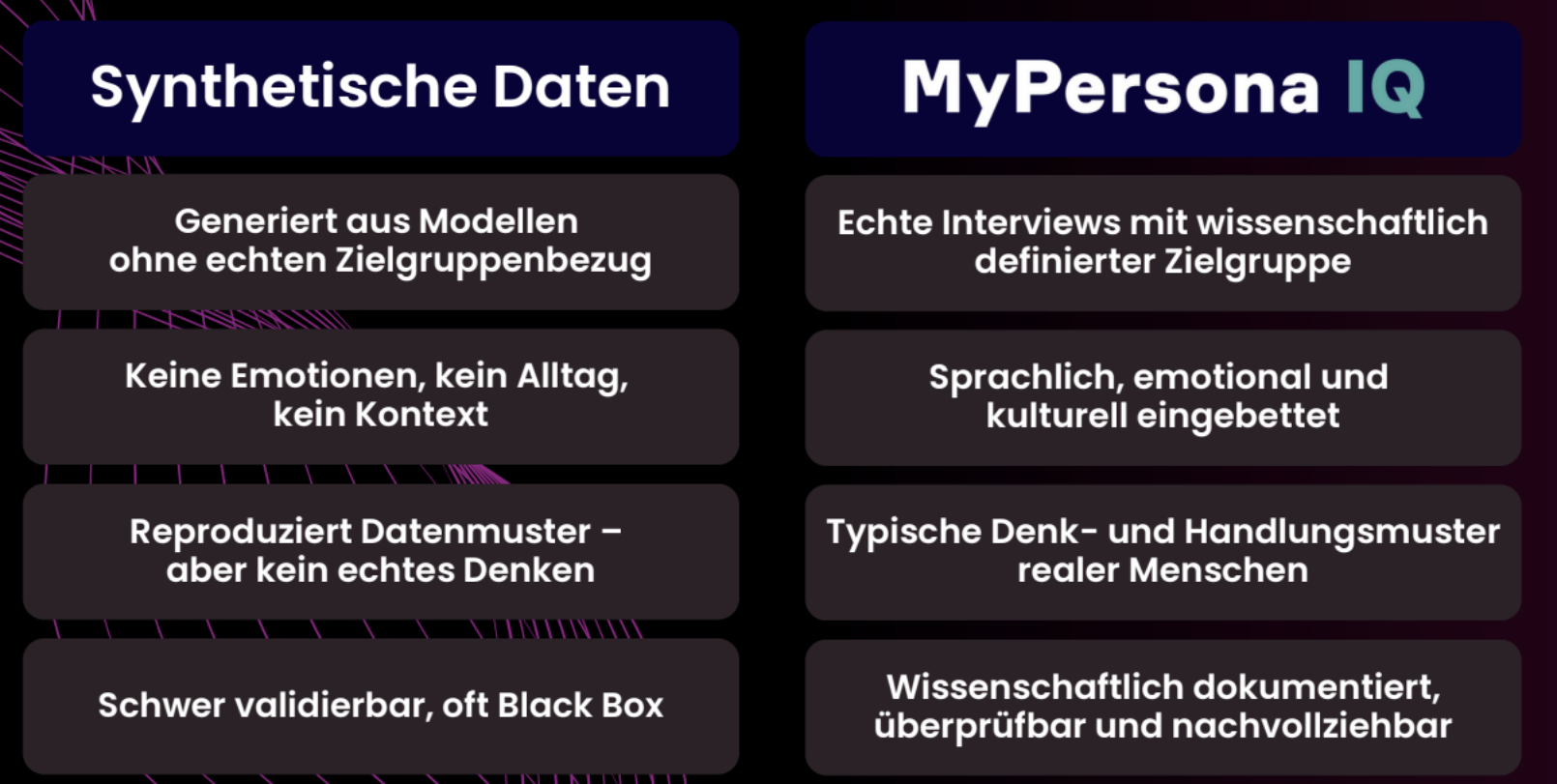
Um den Unterschied zwischen hybriden Ansätzen und rein synthetischen Daten noch einmal klar herauszuarbeiten, lohnt sich eine systematische Gegenüberstellung.
Bei der Datenbasis liegt der fundamentalste Unterschied. Rein synthetische Daten basieren auf den generischen Trainingsdaten des Sprachmodells – eine diffuse Mischung aus Milliarden von Texten aus dem Internet, deren Qualität, Relevanz und Aktualität unklar ist. Hybride Ansätze wie MyPersona IQ basieren dagegen auf authentischen Tiefeninterviews mit der exakten Zielgruppe, die Sie verstehen wollen.
Bei Emotion und Kontext zeigt sich der nächste wesentliche Unterschied. Synthetische Daten simulieren Emotionen und Kontexte, oft auf oberflächliche Weise. Es wirkt vielleicht plausibel, aber es fehlt die Tiefe und Echtheit. Hybride Ansätze hingegen sind sprachlich, emotional und kulturell eingebettet. Die Personas sprechen so, wie echte Vertreter der Zielgruppe sprechen. Sie zeigen emotionale Reaktionen, die auf echten emotionalen Mustern basieren. Sie berücksichtigen den Kontext, weil dieser Kontext in den zugrundeliegenden Interviews explizit erfasst wurde.
Die Validierbarkeit ist ein weiterer kritischer Punkt. Rein synthetische Daten sind eine Black Box, schwer überprüfbar, oft nicht nachvollziehbar. Bei hybriden Ansätzen hingegen ist der gesamte Prozess wissenschaftlich dokumentiert. Sie können nachvollziehen, auf welchen Interviews die Personas basieren. Sie können die ursprünglichen Daten einsehen. Sie können prüfen, ob die Antworten der Personas konsistent mit den echten Interviews sind.
Bei der Denkweise reproduzieren synthetische Daten lediglich statistische Datenmuster. Sie ahmen nach, was häufig vorkommt. Hybride Ansätze dagegen bilden typische Denk- und Handlungsmuster realer Menschen ab – nicht was statistisch wahrscheinlich ist, sondern wie echte Vertreter Ihrer Zielgruppe tatsächlich denken und entscheiden.
Die Reliabilität ist bei synthetischen Daten problematisch, wie wir gesehen haben. Inkonsistenzen und Halluzinationen sind möglich. Hybride Ansätze sind in echten Aussagen verankert, was die Reliabilität deutlich erhöht. Die KI kann zwar neue Formulierungen generieren, aber sie ist durch die Grenzen der realen Interviews gebunden.
Schließlich die Branchen- und Kontextspezifität. Synthetische Daten sind generisch, sie wissen nur das, was in ihren allgemeinen Trainingsdaten vorhanden war. Hybride Ansätze sind hochspezifisch – durch die echten Interviews mit genau Ihrer Zielgruppe erfassen sie die Besonderheiten Ihrer Branche, Ihres Marktes, Ihres spezifischen Kontextes.
Anwendungsfälle in der Praxis für hybride Ansätze bei synthetischen Daten
Hybride Ansätze eignen sich für eine Vielzahl praktischer Anwendungen, bei denen sowohl Qualität als auch Geschwindigkeit wichtig sind. Schauen wir uns einige konkrete Beispiele an.
Claim- und Kampagnentests
Ein klassischer Anwendungsfall sind Claim- und Kampagnentests. Ihr Kreativteam hat drei verschiedene Claim-Varianten entwickelt und möchte wissen, welche am besten ankommt. Mit MyPersona IQ können Sie alle drei Claims den verschiedenen Personas vorlegen und deren Reaktionen einholen. Die Personas reagieren emotional, intuitiv und nachvollziehbar – ähnlich wie in Live-Interviews. Der Unterschied ist nur, dass Sie keine Wochen für Rekrutierung und Terminkoordination benötigen, sondern die Antworten sofort haben.
Besonders wertvoll ist, dass Sie iterativ arbeiten können. Gefällt der erste Claim nicht? Dann formulieren Sie ihn um und testen sofort die neue Version. Im traditionellen Setting würden Sie jetzt eine neue Feldphase planen müssen. Mit hybriden Personas können Sie in Minuten mehrere Iterationen durchlaufen, bis Sie die optimale Formulierung gefunden haben.
Bewertung von Produktideen
Ein zweiter wichtiger Anwendungsfall ist die Bewertung von Produktideen. Sie entwickeln eine Innovation oder denken über Veränderungen in der Verpackung oder im Sortiment nach. Die Personas können Ihnen Feedback geben, wie verschiedene Zielgruppensegmente darauf reagieren würden. Dabei geht es nicht nur um ein pauschales „gut“ oder „schlecht“, sondern um differenziertes Feedback: Was genau begeistert? Wo gibt es Vorbehalte? Welche unerwarteten Probleme könnten auftauchen?
Validierung von Tonalität und Bildwelten
Die Validierung von Tonalität und Bildwelten ist ein dritter Bereich. Sie planen eine Kampagne und sind unsicher, ob die gewählte Ansprache zur Zielgruppe passt. Welche Begriffe erzeugen Resonanz, welche wirken deplatziert? Welche Bilder oder visuellen Metaphern funktionieren, welche erzeugen Ablehnung? Durch den Dialog mit den Personas können Sie solche Fragen klären, bevor Sie viel Geld in die Produktion stecken.
Interaktive Workshops
Schließlich eignen sich hybride Personas hervorragend, um Workshops interaktiver zu machen. Stellen Sie sich eine Strategiesitzung vor, in der über die Ausrichtung für das nächste Jahr diskutiert wird. Traditionell würde das Marketingteam versuchen, sich in die Zielgruppe hineinzuversetzen – mit all den Verzerrungen und Projektionen, die dabei unweigerlich auftreten. Mit interaktiven Personas können Sie stattdessen die Zielgruppe gewissermaßen mit an den Tisch holen. „Was würde unsere Hauptzielgruppe zu dieser Idee sagen?“ – einfach fragen, und Sie bekommen eine fundierte Antwort.
Das funktioniert auch in Kreativprozessen oder bei Pitches. Statt endlos darüber zu spekulieren, was die Zielgruppe wohl denken mag, können alle Beteiligten direkt mit der simulierten Zielgruppe in Dialog treten. Das beschleunigt Entscheidungen und reduziert interne Konflikte, weil Sie eine gemeinsame, objektivere Grundlage haben.
Die Rolle des „Human-in-the-Loop“
Ein absolut zentrales Qualitätsmerkmal seriöser hybrider Ansätze ist das Prinzip des „Human-in-the-Loop“ – der Mensch bleibt im Prozess und übernimmt weiterhin die kritische Kontrolle und finale Bewertung.
Konkret bedeutet das: Ein menschlicher Experte mit Methodenkompetenz und Zielgruppenkenntnis validiert kontinuierlich die Ausgaben des Systems. Wenn eine Persona eine Antwort gibt, prüft der Experte: Ist das plausibel? Passt das zu dem, was wir in den ursprünglichen Interviews gelernt haben? Oder wirkt das wie eine Halluzination des Modells?
Der Experte überprüft auch die Konsistenz. Widerspricht die neue Antwort vielleicht einer früheren Aussage derselben Persona? Wenn die Persona letzte Woche sagte, Preis sei absolut entscheidend, und diese Woche plötzlich behauptet, Preis spiele kaum eine Rolle – dann ist das ein Warnsignal. Entweder hat sich der Kontext der Frage geändert, oder das Modell produziert inkonsistente Ausgaben.
Besonders wichtig ist die Interpretation im Kontext der spezifischen Fragestellung. Eine Persona-Antwort ist niemals eindeutig selbsterklärend. Der menschliche Experte muss sie einordnen, nuancieren, mit anderem Wissen kombinieren. Er muss verstehen, was die Antwort im größeren Zusammenhang bedeutet und welche Implikationen sie für die konkrete Entscheidung hat.
Der Experte ist auch der Detektor für Halluzinationen und Inkonsistenzen. Wenn das Modell plötzlich Fakten erwähnt, die nicht stimmen können, oder Argumentationslinien entwickelt, die nicht zur Zielgruppe passen, muss das erkannt und korrigiert werden. Ein ungeschulter Nutzer würde solche Probleme möglicherweise übersehen.
Das Grundprinzip lautet also: Die KI ist ein intelligenter Assistent, aber kein autonomer Entscheider. Die finale Interpretation und daraus abgeleitete Handlungsempfehlungen obliegen immer dem menschlichen Forscher. Dieser bringt seine Expertise, sein kritisches Denken, sein Verständnis für Nuancen und Kontext ein. Die KI beschleunigt und skaliert, aber ersetzt nicht die menschliche Urteilskraft.
Dieser Human-in-the-Loop ist nicht optional, sondern essentiell. Hybride Ansätze, die auf dieses Element verzichten und die KI-Ausgaben ungefiltert als bare Münze nehmen, verlieren einen Großteil ihrer Qualität und Zuverlässigkeit.
Synthetische Daten: Handlungsempfehlungen für die Praxis
Nach all der Theorie und Analyse wollen wir nun konkret werden. Wie sollten verschiedene Gruppen von Praktikern mit synthetischen und hybriden Daten umgehen? Hier sind differenzierte Empfehlungen für unterschiedliche Rollen.
Für Marktforscher und Insights-Manager:
Als Marktforscher tragen Sie die professionelle Verantwortung für die Qualität der Erkenntnisse, die Sie liefern. Folgende Grundsätze sollten Ihre Arbeit leiten:
Bleiben Sie kritisch gegenüber jeder Studie, die auf synthetischen Daten basiert. Nur weil etwas technisch möglich ist und schicke Grafiken produziert, heißt das nicht, dass es valide ist. Hinterfragen Sie systematisch: Auf welcher Datenbasis wurde das generiert? Wie wurde validiert? Welche Limitationen bestehen? Würden Sie auf Basis dieser Daten selbst eine wichtige Entscheidung treffen?
Fordern Sie Transparenz von Anbietern und Dienstleistern. Lassen Sie sich genau erklären, wie die Daten entstanden sind. Welche Sprachmodelle wurden verwendet? Mit welchen Prompts? Wie wurde die Qualität gesichert? Wenn diese Fragen nicht zufriedenstellend beantwortet werden können, sollten die Alarmglocken läuten.
Investieren Sie in Hybridität. Die Kombination aus echter Forschung und KI-Augmentierung ist der vielversprechendste Weg. Das erfordert zwar initiale Investitionen, zahlt sich aber durch höhere Qualität und langfristige Nutzbarkeit aus.
Etablieren Sie Quality Gates in Ihrem Unternehmen. Definieren Sie klare Kriterien, wann synthetische oder hybride Daten akzeptabel sind und wann klassische Primärforschung unverzichtbar ist. Machen Sie diese Kriterien transparent und setzen Sie sie konsequent durch, auch wenn das manchmal unbequem ist.
Bleiben Sie am Ball der technologischen Entwicklung. Dieses Feld entwickelt sich rasant, und kontinuierliches Lernen ist essentiell. Besuchen Sie Konferenzen, lesen Sie aktuelle Forschung, experimentieren Sie mit neuen Tools – aber immer mit dem kritischen Bewusstsein eines Methodikers.
Für Entscheider und Auftraggeber:
Als Entscheidungsträger, der Marktforschung in Auftrag gibt und deren Ergebnisse nutzt, sollten Sie folgendes beachten:
Fragen Sie immer nach der Methodik. Lassen Sie sich nicht von schnellen Ergebnissen oder günstigen Preisen blenden. Wenn eine Studie deutlich schneller und billiger ist als vergleichbare Projekte, fragen Sie nach dem Warum. Oft liegt der Grund in der Verwendung synthetischer Daten.
Bewerten Sie das Risiko Ihrer Entscheidung. Je höher die Investition, je weitreichender die strategische Bedeutung, desto höher müssen die Qualitätsanforderungen an die Datenbasis sein. Für eine Kampagne mit siebenstelligem Budget rechtfertigen synthetische Daten allein keine Freigabe.
Fordern Sie einen Mix aus Datenquellen. Bestehen Sie darauf, dass synthetische oder hybride Ansätze zumindest stichprobenartig durch echte Daten validiert werden. Ein guter Ansatz: Nutzen Sie hybride oder synthetische Daten für schnelle erste Tests, aber validieren Sie vor finalen Entscheidungen mit echter Forschung.
Nutzen Sie die Geschwindigkeit synthetischer Ansätze richtig. Sie sind hervorragend für frühe Entwicklungsphasen, für das Testen vieler Varianten, für explorative Fragen. Aber ziehen Sie für finale Go/No-Go-Entscheidungen echte Daten heran.
Bauen Sie eigene Kompetenz auf. Sie müssen kein Methodenexperte werden, aber verstehen Sie die Grundlagen. Nur dann können Sie kompetent mitreden und die richtigen Fragen stellen. Investieren Sie in Workshops oder Schulungen für sich und Ihr Team.
Für Forscher und Akademiker:
Als Wissenschaftler haben Sie eine besondere Verantwortung, Standards zu setzen und die Qualität der Forschung zu sichern.
Validieren Sie rigoros. Jede Studie, die synthetische Daten verwendet, braucht umfassende Validierung. Vergleichen Sie mit echten Daten, nutzen Sie verschiedene Sprachmodelle, prüfen Sie Sensitivität und Robustheit. Behandeln Sie synthetische Daten mit derselben methodischen Strenge wie jede andere Datenquelle.
Seien Sie absolut transparent in Ihren Publikationen. Dokumentieren Sie genau, welche Tools Sie verwendet haben, welche Versionen der Sprachmodelle, welche Prompts Sie eingesetzt haben. Andere Forscher müssen in der Lage sein, Ihre Arbeit zu replizieren – und das geht nur mit vollständiger Transparenz.
Replizieren Sie Ihre eigenen Ergebnisse. Führen Sie dieselbe Analyse mit verschiedenen LLMs durch. Wenn GPT-4, Claude und Gemini zu substanziell unterschiedlichen Ergebnissen führen, dann ist das ein massives Warnsignal für die Robustheit Ihrer Befunde.
Publizieren Sie auch Negativergebnisse. Die wissenschaftliche Community muss wissen, wo synthetische Daten versagen, nicht nur wo sie funktionieren. Ein „Publication Bias“ zugunsten positiver Ergebnisse wäre fatal, weil er ein verzerrtes Bild der Möglichkeiten dieser Technologie zeichnet.
Entwickeln Sie Standards. Wir brauchen akzeptierte Qualitätskriterien für AI-gestützte Forschung. Was sind Mindestanforderungen für Validierung? Welche Transparenzpflichten sollten gelten? Wie sollten Limitationen kommuniziert werden? Arbeiten Sie in Fachgesellschaften und Editorial Boards daran, solche Standards zu etablieren.
Faktenbasierte Steuerung statt Simulation
Nach dieser umfassenden Betrachtung synthetischer Daten, ihrer Möglichkeiten und Grenzen, ihrer Risiken und Chancen, ist es Zeit für ein klares Fazit.
Synthetische Daten sind gekommen, um zu bleiben. Das steht außer Frage. Die Technologie ist faszinierend, sie wird sich weiterentwickeln, und sie bietet tatsächlich wertvolle Möglichkeiten – für explorative Studien, für Methodentests, für schnelle erste Einschätzungen. Es wäre töricht, diese Werkzeuge pauschal abzulehnen.
Aber – und dieses Aber ist entscheidend – synthetische Daten sind kein Ersatz für die fundamentale Aufgabe der Marktforschung: die echte, repräsentative Stimme des Marktes zu hören und zu verstehen. Sie können ein Werkzeug sein, ein Hilfsmittel, eine Ergänzung. Aber sie können nicht das Fundament bilden, auf dem weitreichende Entscheidungen getroffen werden.
Die zentrale Botschaft dieses Kapitels lässt sich in einem Satz zusammenfassen: Synthetische Modelle können das Vertrauen in eine Datenbasis nicht im selben Maße bieten wie validierte Primärstudien mit echten Menschen.
Warum ist das so? Weil echte Marktforschung mehr leistet als nur das Sammeln von Antworten. Sie ersetzt das „Bauchgefühl“ durch objektive Daten, ja. Aber sie tut noch mehr: Sie erfasst die Nuancen, Widersprüche und Komplexitäten echter menschlicher Entscheidungsprozesse. Sie findet die unartikulierten Bedürfnisse, die verborgenen Vorbehalte, die kulturellen Eigenheiten. All das, was zwischen den Zeilen steht und was oft entscheidender ist als das, was explizit gesagt wird.
Dieses tiefe Verständnis lässt sich nicht durch Algorithmen simulieren, so leistungsfähig diese auch sein mögen. Ein Sprachmodell kann statistische Muster reproduzieren, aber es kann nicht die Erfahrung einer Geschäftsführerin nachempfinden, die vor zwanzig Jahren einmal mit einem ähnlichen Produkt gescheitert ist und deshalb heute vorsichtig ist. Es kann nicht die politischen Dynamiken in einem mittelständischen Familienunternehmen erfassen, die oft mindestens so wichtig sind wie rationale Produktmerkmale.
Der Weg nach vorn ist klar: Er ist hybrid. Nutzen Sie die Power von KI für Analyse, Skalierung und Interaktivität. Lassen Sie Algorithmen das tun, was sie gut können – große Datenmengen verarbeiten, Muster erkennen, schnell Varianten durchspielen. Aber verankern Sie alles in der Realität echter Menschen mit echten Erfahrungen, Emotionen und Kontexten.
Beginnen Sie mit solider qualitativer Forschung. Führen Sie echte Gespräche mit echten Vertretern Ihrer Zielgruppe. Investieren Sie die Zeit und das Geld, um wirklich zu verstehen, wie diese Menschen denken, was sie antreibt, was sie zögern lässt. Erst auf diesem Fundament können Sie dann KI-gestützte Werkzeuge aufsetzen, die diese Erkenntnisse skalieren und interaktiv nutzbar machen.
Und behalten Sie immer den menschlichen Experten im Loop. Lassen Sie KI nicht autonom Entscheidungen treffen oder Empfehlungen aussprechen. Die finale Interpretation, die kritische Bewertung, die Einordnung in den größeren Kontext – das bleibt Aufgabe erfahrener Forscher mit Methodenkompetenz und Zielgruppenkenntnis.
Nur wer die echte Stimme seines Marktes hört – nicht deren statistische Simulation – kann Investitionen sicher steuern und nachhaltige Wettbewerbsvorteile aufbauen. In einer Welt, in der alle Zugang zu denselben KI-Werkzeugen haben, wird gerade das tiefe, authentische Verständnis der eigenen Zielgruppe zum entscheidenden Differenzierungsmerkmal.
Die Faszination für neue Technologien darf uns nicht den Blick dafür verstellen, was wirklich zählt: echtes Verständnis echter Menschen. Marktforschung war immer und bleibt eine zutiefst menschliche Aufgabe – das Bemühen, andere Menschen zu verstehen. KI kann uns dabei unterstützen, beschleunigen, befähigen. Aber ersetzen kann und sollte sie es nicht.
Sie möchten KI in der Marktforschung wirklich professionell nutzen? Dann vereinbaren Sie noch heute ein kostenloses Beratungsgespräch mit uns. Hier finden Sie alle weiteren Kontaktinformationen zu Cogitaris