Von der unmöglichen Aufgabe zur strategischen Goldmine – warum moderne Textanalyse den Unterschied macht und wie Sie Qualität von bloßer Automatisierung unterscheiden
Die wertvollsten Informationen in Ihrem Unternehmen liegen nicht in Excel-Tabellen. Sie stehen in den E-Mails, die Kunden an Ihren Service schreiben. In den Kommentarfeldern Ihrer Zufriedenheitsumfragen. In den Support-Tickets, die täglich eingehen. In den Bewertungen auf externen Portalen. Unsere Geschäftswelt besteht aus Freitext – und genau dort verbirgt sich das, was Sie wirklich wissen müssen.
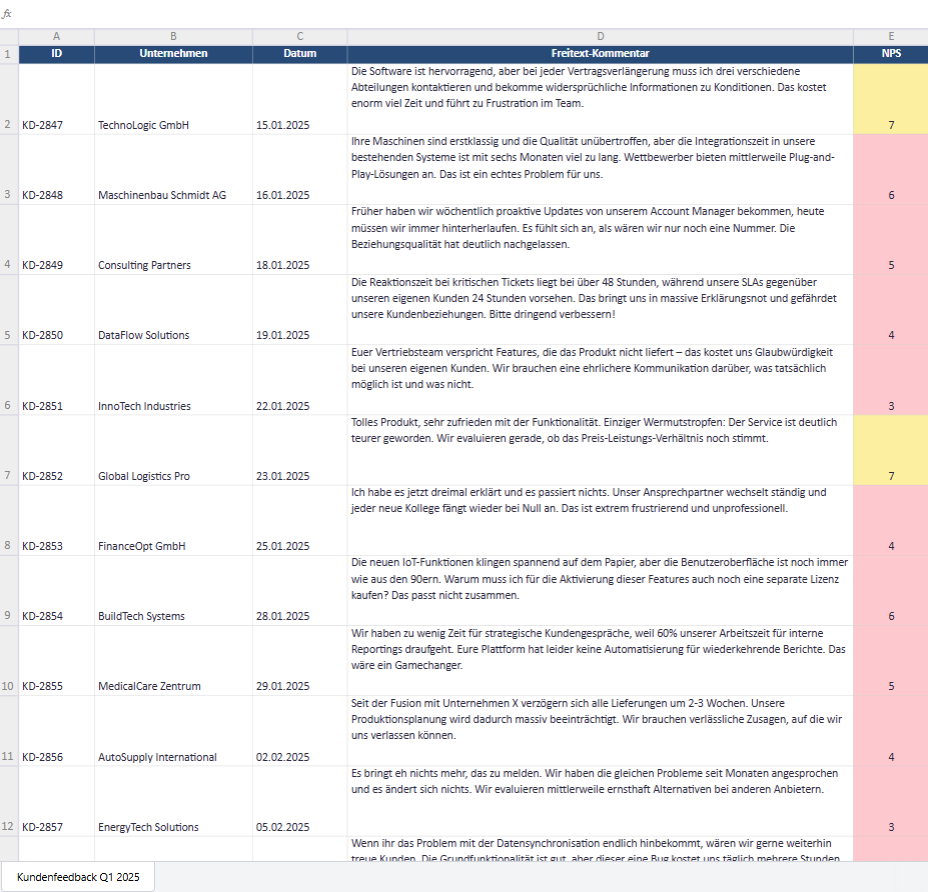
Während Kennzahlen wie der Net Promoter Score oder Sternebewertungen Ihnen sagen, dass etwas nicht stimmt, verrät erst der Freitext das entscheidende Warum. Ein NPS von 42 ist eine Zahl. Aber erst die Aussage „Euer Vertriebsteam verspricht Features, die das Produkt nicht liefert – das kostet uns Glaubwürdigkeit bei unseren eigenen Kunden“ gibt Ihnen die Handhabe zum Handeln.
Warum Freitextantworten im B2B Gold wert sind
Im B2B-Kontext sind Freitextantworten noch wertvoller als im Konsumentengeschäft. Die Gründe liegen auf der Hand: B2B-Kunden sind Profis, die Ihre Branche kennen. Sie artikulieren sich präzise. Sie benennen konkrete Prozesse, technische Details und geschäftliche Auswirkungen. Ein B2B-Kunde schreibt nicht „Service war schlecht“, sondern: „Die Reaktionszeit bei kritischen Tickets liegt bei über 48 Stunden, während unsere SLAs gegenüber unseren eigenen Kunden 24 Stunden vorsehen. Das bringt uns in Erklärungsnot.“
Konkrete Beispiele aus der Praxis:
Beispiel 1: Der verborgene Prozessfehler
Ein Softwareanbieter erhält durchweg positive Bewertungen für sein Produkt (NPS 68), aber die Verlängerungsrate stagniert. In den Freitexten zeigt sich: „Die Software ist hervorragend, aber bei jeder Vertragsverlängerung muss ich drei verschiedene Abteilungen kontaktieren und bekomme widersprüchliche Informationen zu Konditionen.“ Das Problem ist nicht das Produkt, sondern ein interner Abstimmungsfehler zwischen Vertrieb, Buchhaltung und Kundenerfolg. Diese Information würde in keiner Multiple-Choice-Frage auftauchen.
Beispiel 2: Die unterschätzte Kaufbarriere
Ein Maschinenbauunternehmen wundert sich über stagnierende Verkäufe trotz technischer Überlegenheit. Die quantitative Umfrage zeigt: Produktqualität exzellent, Preis akzeptabel. Doch in den Freitexten steht wiederholt: „Ihre Maschinen sind erstklassig, aber die Integrationszeit in unsere bestehenden Systeme ist mit sechs Monaten zu lang. Wettbewerber X bietet Plug-and-Play-Lösungen.“ Die wahre Kaufbarriere ist nicht Qualität oder Preis, sondern Time-to-Value – eine Erkenntnis, die nur aus offenen Antworten gewonnen werden kann.
Beispiel 3: Der Dominoeffekt zwischen Team und Kunde
Ein Dienstleistungsunternehmen führt parallel Mitarbeiter- und Kundenbefragungen durch. In der Mitarbeiterbefragung steht: „Wir haben zu wenig Zeit für Kundengespräche, weil 60% unserer Arbeitszeit für interne Reportings draufgeht.“ In der Kundenbefragung zeitgleich: „Früher haben wir regelmäßig proaktive Updates bekommen, heute müssen wir immer hinterherlaufen.“ Wenn das Team unzufrieden ist, wirkt sich das auf den Kunden aus – und nur die Freitextanalyse macht diese Kausalität sichtbar und belegbar.
Das Problem: Früher praktisch nicht auswertbar
Jahrzehntelang waren Freitextantworten ein Fluch und Segen zugleich. Sie enthielten die wertvollsten Informationen, waren aber praktisch nicht systematisch auswertbar. Die manuelle Codierung – bei der Teams von Werkstudenten monatelang Kommentare in vordefinierte Kategorien pressten – war langsam, teuer und notorisch unzuverlässig. Ein Codierer interpretierte „zu kompliziert“ als Kritik an der Bedienbarkeit, der nächste als Kritik an der Preisstruktur.
Die Alternative war das berüchtigte Cherry-Picking: Man suchte sich drei besonders plastische Zitate für die Vorstandspräsentation heraus. Das Problem: Diese Zitate waren nie repräsentativ. Man wusste nie, ob das ausgewählte Zitat eine weit verbreitete Meinung oder eine absolute Ausnahme darstellte. Entscheidungen auf Basis von Einzelmeinungen zu treffen, ist gefährlich – aber genau das geschah jahrelang, weil es keine bessere Methode gab.
Frühe automatisierte Ansätze – das bloße Zählen von Wörtern oder die Suche nach Keyword-Listen – waren kaum besser. Sie erkannten nicht, dass „nicht zufrieden“ und „sehr zufrieden“ trotz des gemeinsamen Wortes „zufrieden“ Gegensätze sind. Sie verstanden keine Ironie, keinen Kontext und keine Aspekte. Ein Satz wie „Produkt hervorragend, Service katastrophal“ wurde als „neutral“ klassifiziert, weil sich positive und negative Wörter statistisch aufhoben.
Der Wendepunkt: Was moderne KI anders macht

Mit dem Durchbruch bei Large Language Models (LLMs) hat sich die Situation fundamental geändert. Diese Systeme verstehen Sprache nicht mehr über simple Wort-Statistiken, sondern erfassen semantische Zusammenhänge. Sie erkennen, dass „zu teuer“, „Preisschock“ und „nicht im Budget“ das gleiche Konzept beschreiben, auch wenn kein einziges Wort identisch ist. Sie verstehen grammatikalische Bezüge: Wenn ein Kunde schreibt „Der Berater war kompetent, aber er hatte zu wenig Zeit“, weiß die KI, dass sich „er“ auf den Berater bezieht, nicht auf die Kompetenz.
Noch beeindruckender: Gefühlslagen werden erkennbar.
Moderne Systeme gehen weit über die binäre Unterscheidung „positiv/negativ“ hinaus. Sie erkennen Frustration („Ich habe es jetzt dreimal erklärt und nichts passiert“), Resignation („Es bringt eh nichts, das zu melden“), Hoffnung („Wenn ihr das hinbekommt, wären wir gerne weiterhin Kunde“) oder versteckte Abwanderungsgedanken („Wir evaluieren gerade Alternativen“). Diese emotionalen Nuancen sind kritisch: Ein frustrierter Kunde ist noch zu retten, ein resignierter meist nicht mehr.
Ebenso fundamental ist die aspektbasierte Analyse. Ein Kommentar wie „Tolles Produkt, aber viel zu teurer Service“ wird nicht mehr pauschal als „gemischt“ abgestempelt, sondern differenziert aufgeschlüsselt: Produkt positiv, Service negativ (Aspekt: Preis). Das ermöglicht es Ihnen, genau zu verstehen, wo Ihre Stärken und wo Ihre Schwächen liegen – und das nicht anekdotisch, sondern über tausende von Kommentaren hinweg quantifizierbar.
Nicht alle KI-Systeme sind gleich: Warum die Wahl des richtigen Tools entscheidend ist
Der Hype um ChatGPT und ähnliche Tools hat viele Unternehmen dazu verleitet zu glauben, KI-gestützte Textanalyse sei jetzt „gelöst“ – man könne einfach seine Kundendaten in ein öffentliches oder halb angepasstes Tool wie Microsoft Azure kopieren und bekomme fertige Analysen. Die Realität ist komplexer und die Unterschiede zwischen generischen und spezialisierten Systemen sind gravierend.
Problem 1: Generische LLMs liefern Prosa, keine Daten
Wenn Sie ChatGPT fragen „Was sagen meine Kunden über den Preis?“, erhalten Sie eine eloquente Zusammenfassung: „Einige Kunden empfinden den Preis als hoch, während andere das Preis-Leistungs-Verhältnis als angemessen bewerten. Es gibt vereinzelt Hinweise darauf, dass die Preistransparenz verbessert werden könnte.“ Das klingt professionell, ist aber für eine ernsthafte Analyse wertlos.
Für Ihr Management-Dashboard brauchen Sie harte Fakten: „Von 2.847 analysierten Kommentaren kritisieren 407 (14,3%) den Preis. Davon beziehen sich 312 auf absolute Höhe, 95 auf mangelnde Transparenz. Die Kritik ist besonders ausgeprägt im Segment Mittelstand (22,1%) und fast nicht vorhanden bei Enterprise-Kunden (3,2%).“ Das ist der Unterschied zwischen einer netten Geschichte und handlungsrelevanten Daten.
Spezialisierte Textanalysesysteme sind darauf trainiert, strukturierte, quantifizierbare Ergebnisse zu liefern. Jede Aussage ist mit konkreten Zahlen hinterlegt, jede Kategoriezuordnung ist nachvollziehbar. Sie können Entwicklungen über Quartale tracken, Segmente vergleichen und ROI-Berechnungen durchführen – weil Sie mit echten Statistiken arbeiten, nicht mit Prosa.
Problem 2: Mangelnde Reliabilität macht echtes Tracking unmöglich
Generische LLMs sind kreative Systeme. Sie sind nicht deterministisch – das heißt, bei der gleichen Eingabe liefern sie unterschiedliche Ausgaben. Das ist für kreatives Schreiben fantastisch, für wissenschaftliche Analyse aber verheerend.
Ein konkretes Szenario:
Sie analysieren im Januar Ihre Kundenfeedbacks mit ChatGPT. Das System erstellt die Kategorie „Preis-Kritik“ und ordnet 142 Kommentare zu. Im Februar analysieren Sie die nächste Welle – und plötzlich heißt die Kategorie „Kostenbedenken“, erfasst teilweise andere Kommentare und Sie können nicht mehr sicher sagen, ob eine Veränderung von 142 auf 168 Nennungen eine echte Verschlechterung darstellt oder nur eine Laune des Modells. Im März wird daraus „Konditionen-Diskussion“ und Sie haben jede Vergleichbarkeit verloren.
Professionelle Systeme wie Voices lösen dieses Problem durch stabile Kategoriendefinitionen. Das Modell wird auf den spezifischen Use Case trainiert und über Monate konsistent gehalten. Die Definition von „Preis-Kritik“ bleibt im Januar die gleiche wie im Dezember – Sie führen echte „Äpfel-mit-Äpfeln“-Vergleiche durch. Nur so können Sie Trendkurven erstellen, die Wirksamkeit von Maßnahmen messen und verlässliche Forecasts erstellen.
Problem 3: Datenschutz ist keine Nebensache
Wenn Sie Kundendaten in öffentliche KI-Tools wie ChatGPT kopieren, verlassen diese Daten Ihren geschützten Unternehmensraum. Das ist kein theoretisches Risiko: B2B-Feedbacks enthalten regelmäßig vertrauliche Informationen über Geschäftsbeziehungen, interne Prozesse oder strategische Ausrichtungen. Ein Kommentar wie „Seit der Fusion mit Unternehmen X verzögern sich alle Lieferungen“ enthält sensible Marktinformationen.
Für DSGVO-konforme Verarbeitung müssen Textanalysesysteme auf geschützten Servern innerhalb der EU laufen, idealerweise in Deutschland. Die Daten dürfen nicht zum Training globaler Modelle verwendet werden. Zugriffe müssen protokolliert werden. Personenbezogene Daten (Namen, E-Mail-Adressen) müssen automatisch erkannt und maskiert werden, bevor die inhaltliche Analyse beginnt.
Spezialisierte Anbieter wie Cogitaris mit der Voices-Plattform haben diese Anforderungen in ihrer Architektur verankert. Auftragsverarbeitungsvereinbarungen sind standardisiert, Verschlüsselung ist selbstverständlich, rollenbasierte Zugriffskontrolle ist implementiert. Das ist kein „Nice-to-Have“, sondern rechtliche Grundvoraussetzung für den Einsatz im professionellen Umfeld.
Warum marktforscherische Expertise den Unterschied macht
Die Technologie allein ist nicht die Lösung. Eine KI ist ein leistungsfähiges Werkzeug, aber sie versteht nicht von selbst Ihr Geschäftsmodell, Ihre Branche oder Ihre strategischen Prioritäten. Hier kommt die marktforscherische Expertise ins Spiel – und hier trennt sich professionelle Analyse von bloßer Automatisierung.
Prompt Engineering: Die Kunst, die richtigen Fragen zu stellen
Viele DIY-Nutzer von KI-Tools formulieren simple Anweisungen: „Analysiere diese Kommentare und finde Probleme.“ Das Ergebnis ist entsprechend oberflächlich. Professionelles Prompt Engineering ist eine Wissenschaft für sich. Es bedeutet:
- Rollendefinition: Die KI wird instruiert, die Texte aus einer spezifischen Perspektive zu lesen – etwa als erfahrener Beschwerdemanager mit 15 Jahren B2B-Erfahrung.
- Kategorien-Präzision: Jede analytische Kategorie bekommt eine messerscharfe Definition inklusive Positivbeispielen (gehört dazu) und Negativbeispielen (gehört nicht dazu).
- Few-Shot Learning: Die KI erhält handverlesene Beispiele für Grenzfälle, damit sie lernt, wo die Nuancen liegen.
- Strukturierte Ausgabe: Statt Fließtext liefert die KI JSON-formatierte Daten, die direkt in Dashboards einfließen können.
Ein Beispiel aus der Praxis:
Ein Softwareanbieter will verstehen, warum Kunden in den Freitexten „kompliziert“ schreiben. Ein generisches System würde alle Erwähnungen von „kompliziert“ als negativ bewerten. Ein professionell konfiguriertes System differenziert: Bezieht sich „kompliziert“ auf die Ersteinrichtung (einmalig, akzeptabel), auf die tägliche Bedienung (kritisch, unmittelbarer Handlungsbedarf) oder auf die Preisstruktur (kaufhemmend, strategisches Problem)? Diese Unterscheidung entscheidet darüber, welche Abteilung welche Maßnahmen ergreift.
Grounding: Der KI das Fabulieren abgewöhnen
Eine der größten Gefahren bei Large Language Models ist das sogenannte „Halluzinieren“ – die KI generiert mit großer Überzeugung Aussagen, die faktisch nicht in den Daten stehen. Für eine wissenschaftliche Analyse ist das inakzeptabel.
Grounding bedeutet, die KI strikt an die vorliegenden Daten zu binden. Bei Voices wird der KI explizit gesagt: „Nutze ausschließlich diese 2.847 Kundenkommentare. Wenn eine Information dort nicht steht, sage klar, dass sie nicht verfügbar ist. Erfinde nichts.“ Zusätzlich wird die KI gezwungen, für jede Aussage die Quellenkommentare zu nennen, aus denen sie ihre Schlüsse zieht.
Das Ergebnis: Jede Erkenntnis ist nachvollziehbar und belegbar. Wenn im Dashboard steht „14,3% kritisieren die Reaktionszeit“, können Sie per Klick die exakten 407 Kommentare einsehen, die zu dieser Aussage geführt haben. Diese Transparenz ist nicht nur methodisch sauber, sondern auch kritisch für die Akzeptanz im Management. Entscheider müssen darauf vertrauen können, dass hinter jeder Prozentzahl echte Kundenstimmen stehen, keine KI-Fantasien.
Human in the Loop: Qualitätskontrolle bleibt unverzichtbar
Selbst die beste KI macht Fehler. Deshalb setzen professionelle Anbieter auf kontinuierliche menschliche Qualitätskontrolle. Bei Voices läuft das in mehreren Stufen:
- Stichprobenprüfung: Analysten ziehen regelmäßig Zufallsstichproben und prüfen manuell, ob die KI-Zuordnungen korrekt sind.
- Gold Standard Sets: Vorab manuell codierte Datensätze dienen als Benchmark, um Precision (Genauigkeit) und Recall (Vollständigkeit) zu messen.
- Iterative Verfeinerung: Wenn Schwächen identifiziert werden – etwa bei branchenspezifischem Jargon –, werden die Prompts so lange angepasst, bis die Fehlerquote unter 5% liegt.
Dieser Aufwand unterscheidet einen professionellen Service von einem DIY-Tool. Bei letzterem sind Sie auf sich allein gestellt – Sie wissen nie genau, ob Ihre Ergebnisse verlässlich sind. Bei einem Full-Service-Anbieter ist Qualitätssicherung Teil des Leistungsversprechens.
Fallbeispiele: Wo KI-Textanalyse den entscheidenden Unterschied macht
Fallbeispiel 1: Prädiktive Churn-Analyse bei einem SaaS-Anbieter
Ausgangssituation:
Ein Software-as-a-Service-Unternehmen kämpft mit einer steigenden Churn-Rate. Die quantitativen Daten zeigen: Kunden kündigen im Schnitt nach 18 Monaten, aber es gibt keine klaren Muster in den Nutzungsdaten oder demographischen Merkmalen.
Die Textanalyse deckt auf:
Die Analyse von Support-Tickets und Umfrage-Kommentaren über 12 Monate zeigt ein klares Muster: Kunden, die später kündigen, zeigen bereits 6-8 Monate vorher subtile Warnsignale in ihren Texten. Sie wechseln von „wir“ zu „ich“ (Indikator für sinkende organisatorische Verankerung), sie fragen vermehrt nach Exportfunktionen (Vorbereitung auf Migration), und ihre Tonalität wird zunehmend transaktional statt partnerschaftlich („Bitte um Information zu…“ statt „Können wir gemeinsam…“). Zusätzlich tauchen erstmals Vergleiche mit Wettbewerbern auf: „Anbieter X bietet Feature Y bereits seit einem Jahr.“
Die Maßnahme:
Das Unternehmen implementiert ein Frühwarnsystem. Sobald bei einem Kunden drei dieser sprachlichen Marker auftreten, wird automatisch ein Customer Success Manager informiert. Dieser nimmt proaktiv Kontakt auf – nicht mit standardisierten Retention-Angeboten, sondern mit gezielten Fragen zu den in den Texten angedeuteten Problemen. Die Churn-Rate sinkt innerhalb von sechs Monaten um 23%, weil Probleme angegangen werden, bevor Kündigungsentschlüsse gefasst sind.
Fallbeispiel 2: Die Employee-Customer-Connection bei einer Unternehmensberatung
Ausgangssituation:
Eine mittelständische Unternehmensberatung erhält sinkende Scores in Kundenbefragungen, insbesondere beim Punkt „Proaktivität“. Gleichzeitig zeigt die interne Mitarbeiterbefragung eine wachsende Unzufriedenheit mit „administrativem Overhead“.
Die Textanalyse deckt die Verbindung auf:
Die parallele Analyse beider Datensätze zeigt einen direkten Zusammenhang. Mitarbeiter schreiben: „Ich verbringe drei Stunden pro Tag mit internen Status-Calls und E-Mail-Schleifen zu Projektreportings. Für strategische Kundenarbeit bleibt kaum Zeit.“ Kunden schreiben zeitgleich: „Früher haben wir wöchentlich proaktive Updates bekommen, heute müssen wir immer nachhaken. Es fühlt sich an, als wären wir nur noch eine Nummer.“
Die Textanalyse quantifiziert das Problem: 47% der Mitarbeiter-Kommentare erwähnen administrative Belastung, und bei genau jenen Projekten, die von diesen Mitarbeitern betreut werden, liegt die Kundenzufriedenheit 18 Prozentpunkte niedriger als im Durchschnitt. Die Kausalität ist nicht mehr nur Vermutung, sondern datenbasiert belegt.
Die Maßnahme:
Das Unternehmen verschlankt seine internen Reporting-Prozesse radikal, reduziert die Zahl der Status-Meetings um 60% und führt asynchrone Updates ein. Innerhalb von drei Monaten steigt die Mitarbeiterzufriedenheit im Bereich „Arbeitsorganisation“ um 28 Prozentpunkte, und – zeitverzögert um zwei weitere Monate – steigt die Kundenzufriedenheit im Bereich „Proaktivität“ um 21 Prozentpunkte. Wenn das Team unzufrieden ist, wirkt sich das auf den Kunden aus – diese Hypothese ist nun nicht mehr nur eine Weisheit, sondern ein nachgewiesener und quantifizierter Zusammenhang.
Fallbeispiel 3: Markenwechsel von „Qualität“ zu „Innovation“ bei einem Maschinenbauer
Ausgangssituation:
Ein etablierter Maschinenbauer mit 50 Jahren Tradition will sich als Innovationsführer positionieren. Das Marketing investiert massiv in Kampagnen zu Industrie 4.0, KI-Integration und IoT-Fähigkeiten. Die Geschäftsführung will wissen: Kommt die Botschaft an?
Die Textanalyse zeigt die Realität:
Die Analyse von Kundenfeedback, Bewertungsportalen und Social-Media-Erwähnungen über 18 Monate zeigt: Die Wahrnehmung hat sich kaum verschoben. In 68% der analysierten Texte wird das Unternehmen nach wie vor mit Attributen wie „zuverlässig“, „robust“ und „bewährt“ assoziiert. Innovationsbegriffe tauchen nur in 12% der Fälle auf – und davon sind zwei Drittel nicht spontane Nennungen, sondern Reaktionen auf direkte Nachfragen („Was halten Sie von unseren neuen IoT-Features?“).
Noch aufschlussreicher: Wenn Innovation erwähnt wird, steht oft im selben Atemzug eine Einschränkung: „Die neuen Funktionen klingen spannend, aber die Benutzeroberfläche ist noch immer aus den 90ern“ oder „IoT-fähig ist schön, aber warum muss ich für die Aktivierung noch eine separate Lizenz kaufen?“
Die Erkenntnis:
Das Problem ist nicht die fehlende Innovation, sondern die Customer Experience rund um diese Innovation. Die Textanalyse zeigt: Kunden erleben Innovationen als „aufgesetzt“ statt „integriert“. Das Unternehmen justiert seine Strategie: Statt weiterer Feature-Ankündigungen investiert es in die nahtlose Integration dieser Features und in moderne, intuitive Bedienkonzepte. Die nächste Befragungswelle sechs Monate später zeigt: Spontane Nennungen von „modern“ und „innovativ“ steigen auf 31% – weil die Innovation jetzt tatsächlich erlebbar ist, nicht nur beworben.

Fazit: Die Goldmine ist real – aber nur mit den richtigen Werkzeugen zugänglich
Unsere Geschäftswelt besteht aus Freitext. Die wertvollsten Informationen über Ihre Kunden, Ihre Produkte und Ihre Prozesse stehen nicht in Dashboards, sondern in E-Mails, Kommentaren und Support-Tickets. Jahrzehntelang waren diese Informationen praktisch unzugänglich – zu aufwendig in der Auswertung, zu fehleranfällig in der Interpretation.
Moderne KI-gestützte Textanalyse hat dieses Problem grundlegend gelöst. Sie ermöglicht es heute, tausende von Freitextantworten in Stunden statt Monaten auszuwerten, Emotionen zu erkennen, Aspekte zu differenzieren und quantifizierbare Ergebnisse zu liefern. Die Technologie existiert und funktioniert.
Aber – und das ist entscheidend – nicht alle Systeme sind gleich. Der Unterschied zwischen einem generischen LLM und einem spezialisierten Textanalysesystem ist gewaltig:
- Generische Tools liefern Prosa, spezialisierte Systeme liefern Daten
- Generische Tools sind inkonsistent, spezialisierte Systeme garantieren zeitliche Stabilität
- Generische Tools gefährden Datenschutz, spezialisierte Systeme sind DSGVO-konform
Darüber hinaus macht marktforscherische Expertise den Unterschied zwischen Automatisierung und echter Analyse. Prompt Engineering, Grounding, Human-in-the-Loop-Qualitätskontrolle – das sind keine technischen Spielereien, sondern methodische Notwendigkeiten für verlässliche Ergebnisse.
Die Fallbeispiele zeigen: Professionelle Textanalyse identifiziert Churn-Signale, bevor Kunden kündigen. Sie deckt die oft vermutete, aber selten belegte Verbindung zwischen Mitarbeiter- und Kundenzufriedenheit auf. Sie zeigt, ob Ihre Markenbotschaften ankommen oder verpuffen. Das ist keine nette Zusatzinformation – das sind strategische Erkenntnisse, die direkt auf die Profitabilität einzahlen.
Die Goldmine der Freitextantworten ist real. Mit den richtigen Werkzeugen und der richtigen Expertise wird daraus kein Datengrab, sondern Ihr wichtigster strategischer Vorteil.
───
Über Voices:
Voices ist die Full-Service-Textanalyseplattform von Cogitaris. Sie kombiniert modernste KI-Technologie mit marktforscherischer Expertise und liefert DSGVO-konforme Analysen mit garantierter zeitlicher Stabilität. Statt Software zu lizenzieren, erhalten Kunden verlässliche Antworten auf ihre Geschäftsfragen – ohne sich mit technischer Komplexität auseinandersetzen zu müssen.
Kernsatz:
Wenn das Team unzufrieden ist, wirkt sich das auf den Kunden aus – und moderne Textanalyse macht diese Zusammenhänge messbar, nachvollziehbar und handlungsrelevant.
SEO-Keyword:
KI-Textanalyse